Allow trusted crawlers. Control the rest.
Find out which crawlers actually bring value and which ones don't. Allow high-value crawlers, block or paywall low-value ones, and compare crawls with referrals to make decisions with confidence.
Awarded and supported by







Crawler value management
Decide which crawlers create value and enforce the right access policy.
Not every crawler should be treated the same. Atmosvere helps you compare crawler activity with referral outcomes and enforce clear value-based access policies.
- Value vs non-value crawlers
- Identify which crawlers drive measurable value and which consume resources without meaningful referral impact.
- Crawls vs referrals
- Compare crawler activity with actual referral outcomes to decide who should be allowed, limited, monetized, or blocked.
- Simple crawler policy enforcement
- Apply clear allow, paywall, throttle, and block rules without complex operations or constant manual tuning.
- Protect infrastructure and business value
- Reduce unnecessary load while preserving high-value access, so crawler traffic supports your platform instead of draining it.

27% of web traffic comes from good bots
Many of these are crawlers that support discovery, indexing, and visibility. Business success depends on handling them correctly: allow valuable crawlers, limit low-value traffic, and block abusive automation.
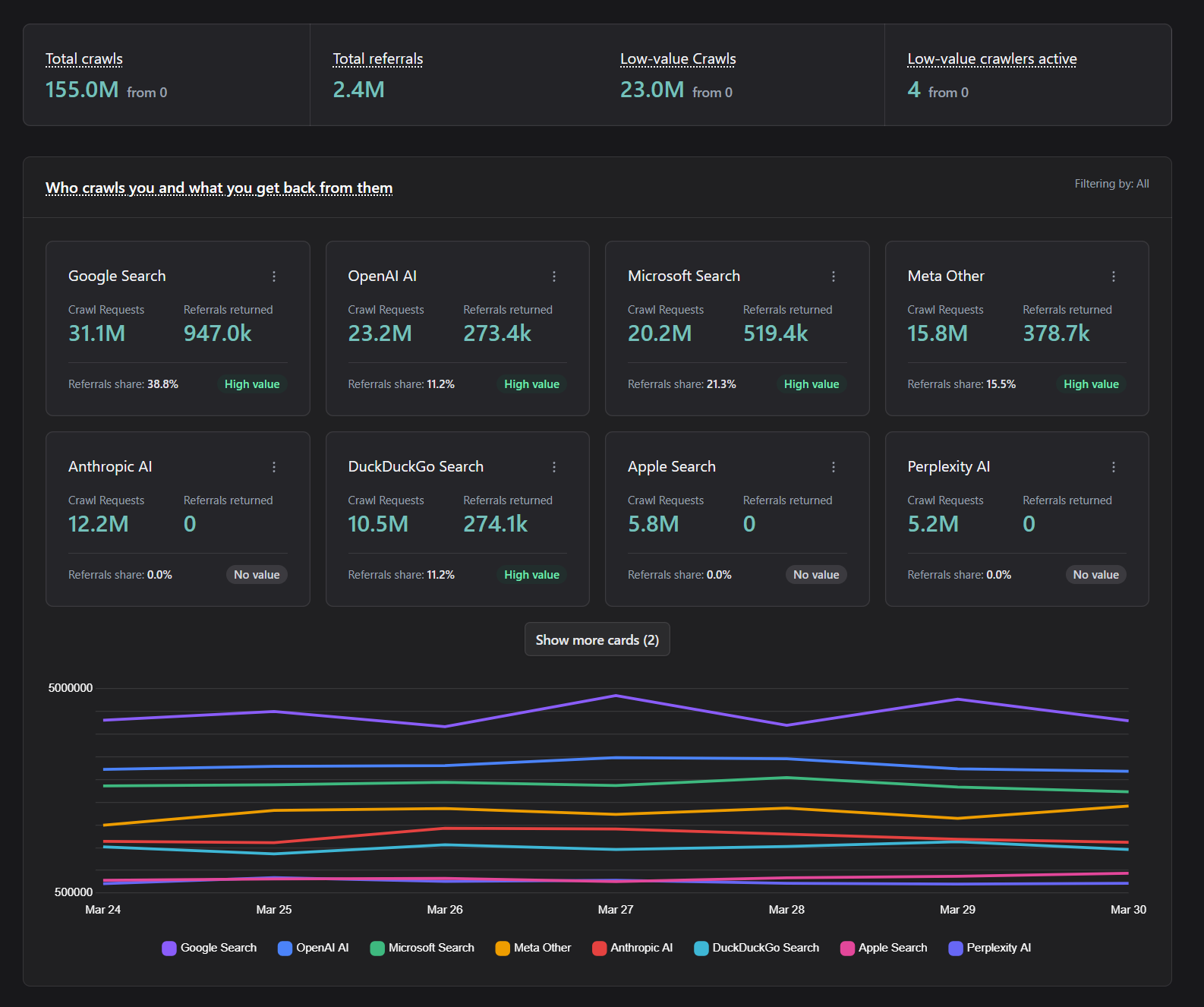
Crawler Analysis
See which crawlers create business value with referral-based evidence.
- Detect crawler traffic.
- Identify crawler behavior patterns and traffic share in real time across your platform.
- Measure outcomes in the admin-panel.
- See which crawlers convert into meaningful referrals and where low-value traffic creates cost.


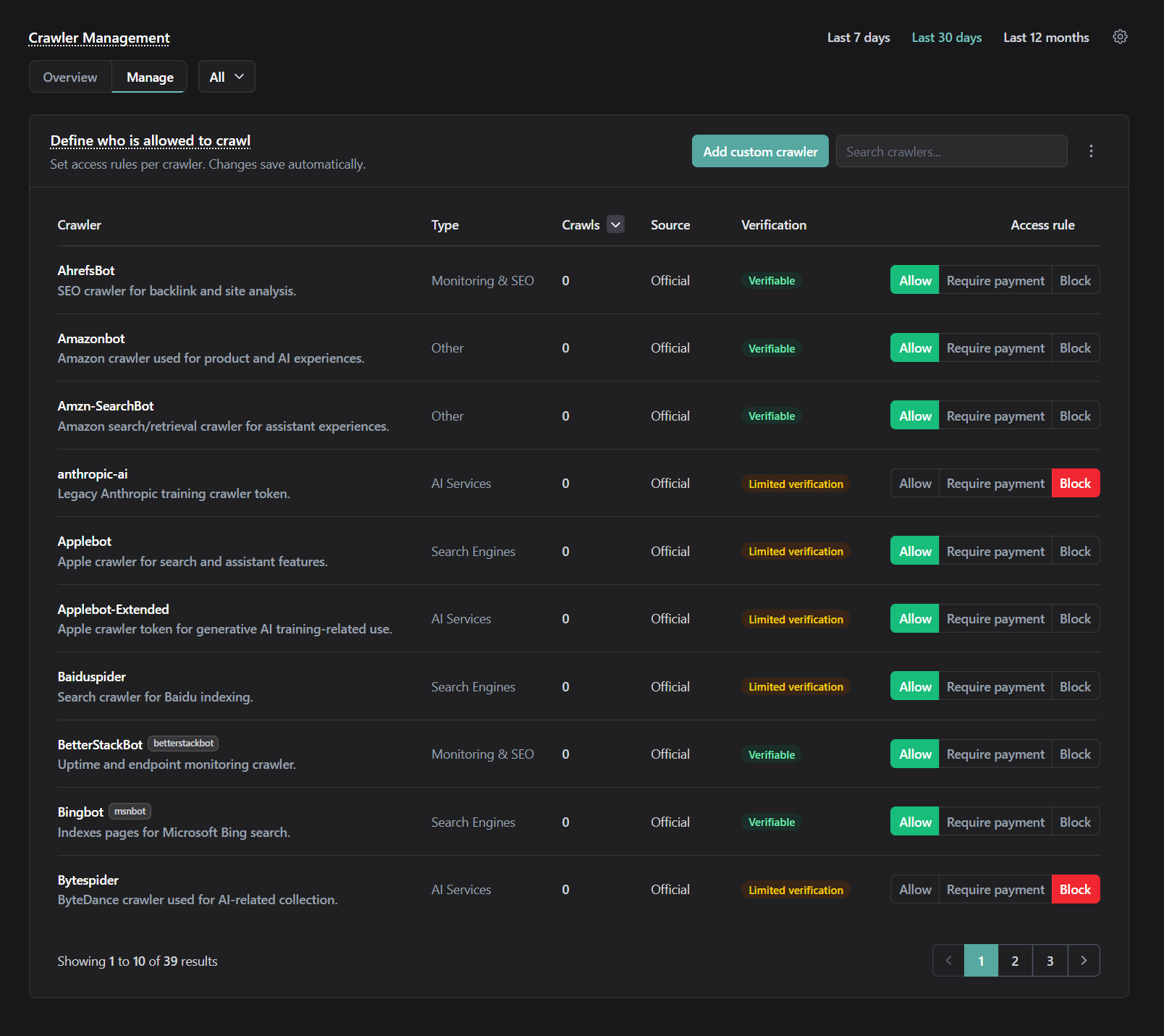
Crawler Management
Allow, paywall, limit, or block with simple rules.
- Enforce rules per crawler.
- Apply allow, throttle, paywall, or block policies based on value and risk.
- Protect your infrastructure.
- Reduce unnecessary crawler load and keep capacity available for real users and valuable traffic.
Key benefits
Keep SEO. Control load. Stay in control.
Atmosvere lets you manage crawler access while protecting infrastructure and preserving the integrity of indexing and analytics.
- SEO-safe allowlisting
- Whitelist trusted crawler traffic so legitimate indexing and analytics stay intact.
- Risk-based enforcement
- Decide based on behavior signals so spoofed clients don’t slip through with a fake identity.
- Configurable at your pace
- Tune rules in the admin-panel and iterate without redeploying your core stack.
- Infrastructure protection
- Reduce crawler load and protect capacity by restricting abusive request patterns.
- Privacy-first approach
- Designed to minimize invasive tracking while still enabling crawler detection and control.
Frequently asked questions
Learn how crawler access rules work and how to measure results in the admin-panel.
- Will crawler management hurt SEO?
- No — the goal is to allow trusted SEO crawlers while restricting abusive automation. You control rules via allowlists and visibility in the admin-panel.
- What’s the difference between allowlists and denylist rules?
- Allowlists ensure trusted crawlers keep access. Denylist/restriction rules reduce or block others based on risk signals and traffic behavior.
- How do we see which crawlers are causing issues?
- The admin-panel provides crawler views and trends so you can identify sources and adjust enforcement based on outcomes.
- How do we integrate with our stack?
- Use the protection integration approach: connect decisioning into the traffic path. Then configure crawler rules in the admin-panel.
Testimonials
Trusted by teams across Europe who rely on Bot Shield to protect applications, APIs, and infrastructure.
“Atmosvere was easy to integrate, simple to run, and the team behind it provides highly responsive, personal support whenever needed.”

“Atmosvere gave us full control over automated traffic. We reduced unnecessary load, blocked bots, managed crawlers, and improved system stability—while also strengthening our marketing activities without impacting real users.”

“Anyone who uses Atmosvere is sending a clear signal about a sustainable and digitally ethical platform economy.”

“Atmosvere is really easy to implement and has been evolving quickly - the team is always open in providing new insights and turning feedback into real improvements.”
European Trust
Built for European trust from the Austrian Alps with strong, simple, privacy-first protection.
- Visitors analyzed
- >400M
- Platforms protected
- >1k
- Data residency
- EU only
- Compliance model
- GDPR-first
Manage crawler value with confidence
Identify valuable crawlers, control non-value traffic, and protect infrastructure with simple rules that support long-term business growth.